Currently, I am a PhD of student Intelligent Systems Engineering under Prof. Thomas Sterling at Center for Research in Extreme Scale Technologies CREST which is part of School of Informatics and Computing at Indiana University, Bloomington
I recently recieved my masters degree in Computer Science --> Proof I am working on writing Irregular Applications for Dynamic Adaptive Runtime System.
Check out CoMD ported to HPX
Prior to comming to Indiana University I was Research Developer at the Center for High Performance Scientific Computing in NUST-Pakistan. My research and development focused on Java based message-passing systems for High Performance Computing (HPC). I am one of the developers of an open source Java MPI library called MPJ Express, which an open source Java message passing library that allows application developers to write and execute parallel applications for multicore processors and compute clusters/clouds. The software is distributed under the MIT (a variant of the LGPL) license.
Publications:
Journal Paper:
Ansar Javed, Bibrak Qamar, Mohsan Jameel, Aamir Shafi, Bryan Carpenter Towards Scalable Java HPC with Hybrid and Native Communication Devices in MPJ Express, International Journal of Parallel Programming, 2015, pp 1-31
Conference Paper:
Bibrak Qamar, Ansar Javed, Mohsan Jameel, Aamir Shafi and Bryan Carpenter Design and Implementation of Hybrid and Native Communication Devices for Java HPC, Procedia Computer Science 29 (2014) 184–197
------ Nostalgia ------
I worked on Oil Reservoir Simulation project at UAE University. My work include implementing and assessing different sparse matrix storage formats for linear solvers used to solve system of linear equatuions.
Apart from the computational resources at HPC lab we also used Amazon EC2 cloud instances to assess the behaviour of algebraic kernels. In a cloud environment the resources are heterogeneous and can be shared by other users at a time, therefore, not all nodes may have same FLOPs to offer and not all interconnects may have the same bandwidth. Platform oblivious distribution of matrix limits the parallelism of algebraic kernels (matrix operations) to the nodes that consume more time cycles. In order to maximizing the system resources and parallelism, we distributed the load in such a way that all the nodes consume same amount of time cycles.
I was also involved in design and implementation of scheduling algorithms for divisible workloads on cloud computing platforms.
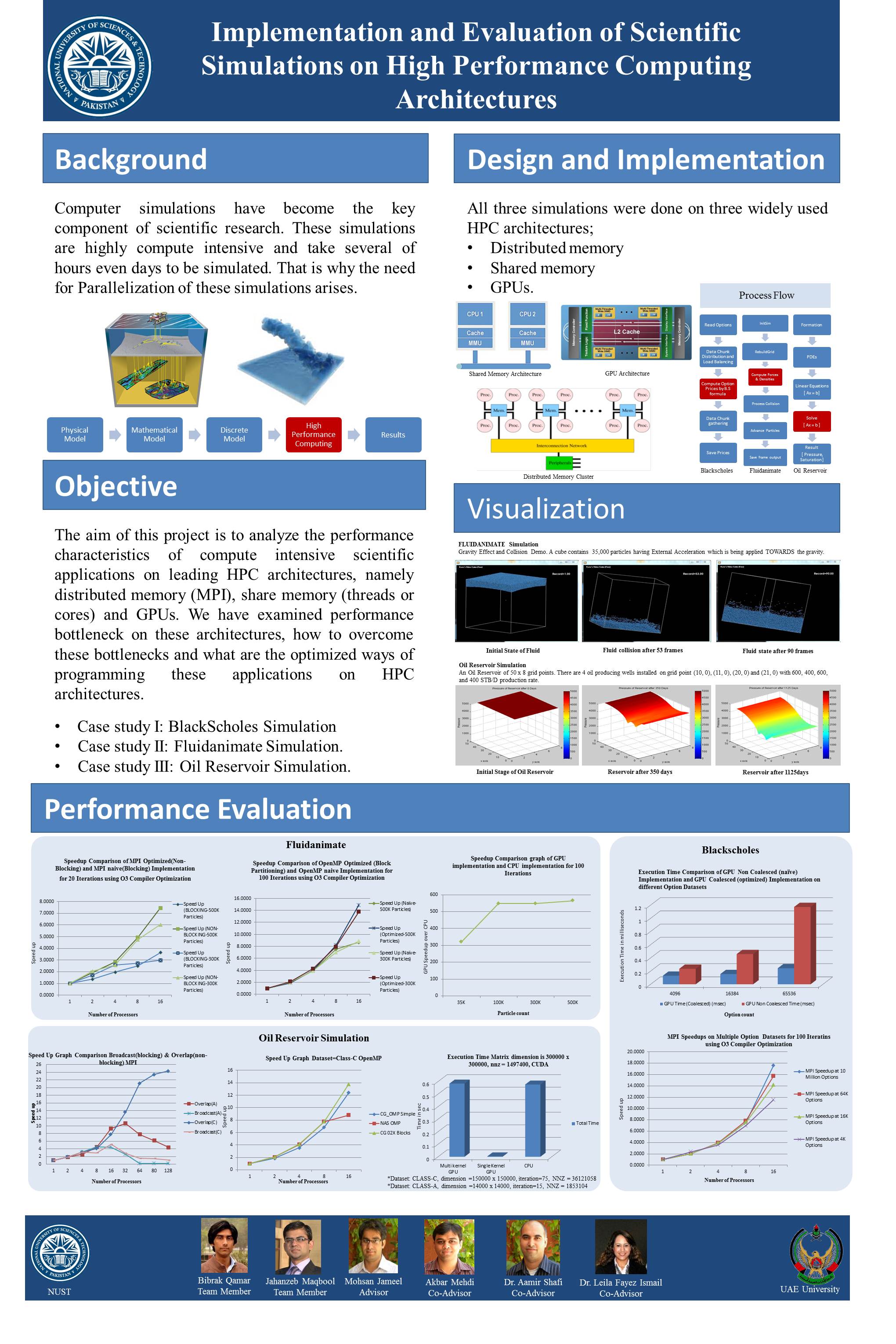
In the project I and my group member Jahanzeb Maqbool did a thorough study of three different scientific simulations on different HPC architectures (SMP, Multicore, Cluster, GPU). These applications namely Molecular Dynamics, Reservoir Simulation and BlackScholes are a representation of diverse data structures and algorithms used in HPC codes in supercomputers.
My part in the project was to implement and study conjugate gradient for three-dimensional single-phase oil reservoir simulation. My work was centered on implementing sparse-matrix formats, domain decomposition, communication patterns and topology that best exploits the underlying architecture.
The Game of Life consists of grid of NxNx cells, where the complexity is O(N2) from conventional single thread perspective. The aim of the study was to understand the theoretical and empirical relationship between size of the grid and number of CUDA threads on the performance, especially the memory bandwidth.
Starting with the simple case,
· Case # 1: total number of cells = total number of threads, where each thread is responsible to operate on only one cell and does O(1) work. Case # 1 works only then N2 <= max threads on GPU.
· Case # 2: Each thread operates on a column of the grid therefore total number of threads = N. Each thread does O(N) work. Case # 2 eliminates the restrictions posed by case # 1 but creates GPU underutilization problem. Case # 2a: Each thread works on a row instead of a column. Theoretically case # 2a is case # 2 but technically it will create memory coalescing issues (low memory bandwidth) if the grid is stored row-wise in a 1D array.
· Case # 3 [not implemented]: is a compromise between case # 1 and case # 2 in which a column is divided horizontally into p chunks. The value of p can be tweaked to increase GPU utilization. If (N/2)<= Max threads, then each thread operates on a chunk of column and does O(N/p) work. If N>Max threads then a thread may get more than one column depending on c where c=(N/Max threads) so a thread does O(cols.N) work. This not only introduces problem of memory coalescing as of case # 2a but also reduces the overall parallelism since for some threads cols > 1 if c is not an integer.
One of the limitations of our model is that the grid is finite and modeled as a torus. Ideally it has to be infinite, using hashlife algorithm, which uses quadtree and hash table to represent the gird. This was out of the scope of the study.
{kind=link}
{kind=link}